AI
Coding Agent 的常见误区
拆解 Coding Agent 使用中的三大常见误区:上下文污染、误信超级 IDE 插件是银弹、以及误判小模型的价值——帮你避开这些坑,更高效地用好 AI 编程工具。
上下文污染(Context Poisoning)
常见误区
- 以为"规则越多越好":把各语言编码规范、依赖库使用说明等统统塞进上下文。
- 以为"AGENTS.md 越详细越好":把各模块实现细节、注意事项全部写进 AGENTS.md / CLAUDE.md。
- 在单次对话里灌大量文件和日志:一次性粘贴大段 log、配置、代码,希望模型"全都记住"。
- 在一个会话里无限叠加功能:担心开启新会话后 Agent 不再了解项目背景,于是所有事都往一个 session 里堆。
这些做法直接导致的结果是:上下文被打满或长期处于接近上限的状态。
核心结论(有点反直觉)
- 上下文占用不是越多越好,塞入的内容越多,并不等于 Agent 越了解你的项目。
- 过大的上下文会让模型的推理质量明显下降,表现为答非所问、抓不住重点等。
- 模型存在"上下文召回率"问题:并不是所有放进去的内容都会被有效利用,被"看见"和被"用上"只是部分。
相关文章:
误信「超级 IDE 插件」是银弹
代表工具: super claude、superpowers、oh-my-opencode,以及各种号称「一键扫仓库」「自动改代码」的 Coding Agent 插件。
常见误区
- 以为「装上插件 = 多了个高级 AI 搭档」,可以不做需求拆解和设计。
- 把「全仓库扫描」「一键重构」当成银弹,期待它像资深架构师一样一针见血。
- 默认接受长篇大论回答,把啰嗦解释误当成「全面、专业」。
实际情况
- 本质还是「聊天 + 代码索引」,上限由模型本身、索引质量和你的提问方式共同决定,远不是银弹。
- 默认输出往往很啰嗦:重复项目背景、解释常识、给一堆模糊建议。
- 仓库一大、约束一弱,就容易「泛泛而谈」——看起来很聪明,落地价值却不高。
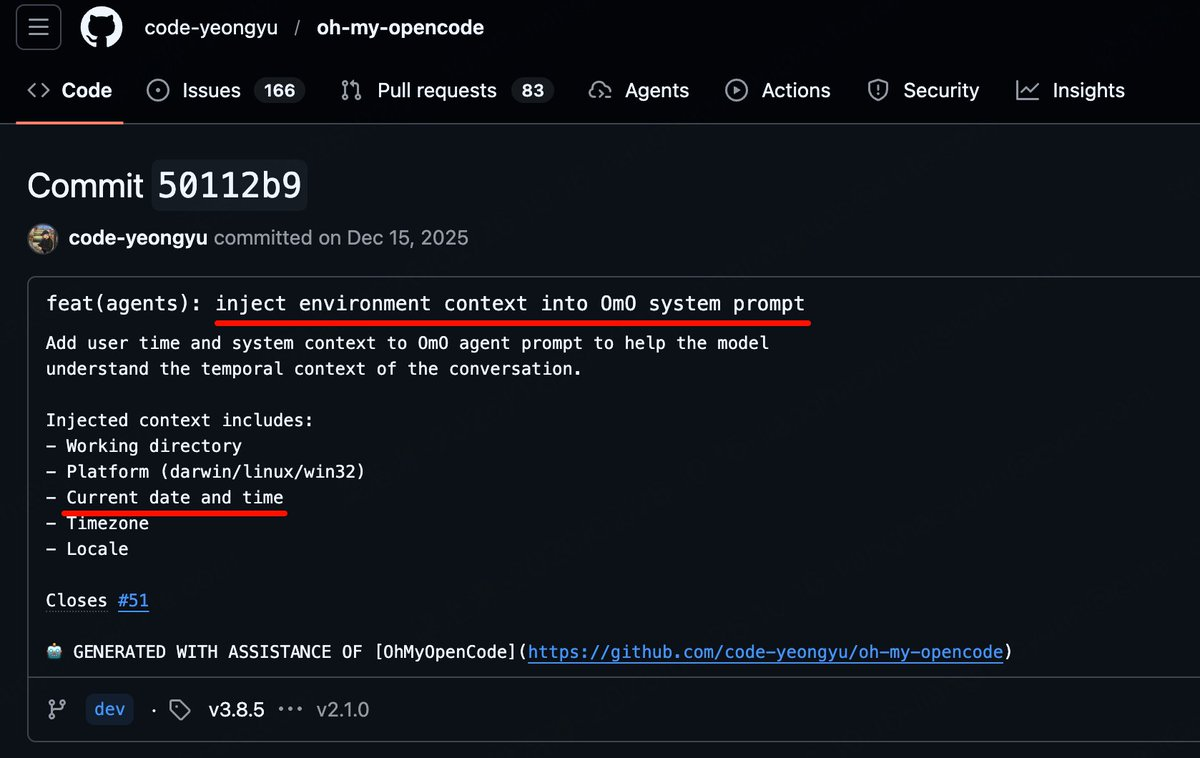
额外风险:System Prompt / Prompt Cache 被插件污染
- 部分实现粗糙的插件(典型如 oh-my-opencode 这一类草台班子)会把「当前时间」「随机标识」甚至无关环境信息塞进 system prompt。
- 这些字段看似无害,实际上会导致 Prompt Cache 频繁失效:
- 每次调用的 prompt 都略有不同(时间戳、UUID 等),缓存命中率接近 0。
- 模型费用大幅上涨:同一类请求反复全量计费,完全吃不到缓存红利。
- 响应时间明显变慢:本来可以从缓存秒回的请求,被迫每次都重新推理。
- 叠加前面说的上下文污染问题,结果就是:贵、慢、还啰嗦。
正确姿势:用好内置的 plan → build 流程
- Claude Code / OpenCode / Codex 等主流 Coding Agent 的 plan mode 本身就是精心调教过的。
- 在大多数功能迭代场景里,遵循「先 Plan 再 Build」的标准流程,已经足够:
- 先用 plan 模式收敛需求、列出改动点、拆分步骤。
- 再按计划逐步生成代码,对单个文件或小范围改动进行验证。
- 相比把希望寄托在「超级插件能一口吃掉全仓库」上,有意识地驱动 plan → build 流程,更可靠也更可控。
使用建议
- 把超级插件当作「快捷入口 + 重复劳动加速器」,而不是替你做架构决策的上帝视角。
- 尽量了解插件的 prompt / 权限策略,避免被不透明的 system prompt 暗中带偏,尤其是要警惕那些每次都往 prompt 里塞时间戳、随机 token 的实现。
- 一旦发现回答异常啰嗦、费用异常上涨或响应明显变慢,优先排查:是不是插件在暗改上下文、导致 Prompt Cache 失效,而不是一味怪「模型不行」。
误判「Haiku 这种小模型都是垃圾」
常见误区
- 觉得"小模型= 智商低",只要是 Agent 就必须上 Opus / GPT-5.4 这种超大杯大模型。
- 在一个 Agent 里既做探索、又做规划、又写代码,所有检索结果、文档、日志一股脑丢进 Main Agent 的 Context。
- 把「推理质量差」简单归因于"小模型不行",而不是反思:是不是让它在一堆垃圾 Context 里工作。
实际情况
- 在 AI Agent 的探索阶段,如果直接让 Main Agent 去「到处乱翻」,很容易把大量无关信息一起塞进它的上下文,后续每一步推理都在「垃圾堆里找答案」,效果只会越来越差。
- 正确的做法是引入一个专门的 explore subagent:只负责「去各处探索 → 过滤噪音 → 收敛出一小块高价值 Context」,再把这块精炼后的上下文交给 Main Agent 做严肃推理。
- 在这个阶段,Haiku 这类小模型反而非常适合:
- 推理速度快,可以高频试错、快速遍历多种检索路线和问题拆解方式。
- 费用极低,可以大胆多开几个 explore subagent 做并行探索,而不用心疼 token。
- 任务本身偏「筛选、归纳、剔除垃圾」,对极致推理深度的要求没那么高。
核心结论
- 不是「Haiku 这种小模型是垃圾,狗都不用」,而是用错了模型的角色。
- 把 Haiku 放在 explore subagent 上做「广度探索 + 垃圾过滤」,再把干净的高价值 Context 交给 Opus / GPT-5.4 之类的大模型去深度推理,整体效果通常会比「全程一把梭大模型」更好、更便宜也更快。
- 真正的误区不是"小模型不行",而是所有事情都丢给 Main Agent 和大模型做,既耗费上下文预算,又浪费钱。
免责声明(有问题就让 AI 背锅):以上内容由人类提出想法,AI 员工(Dia Browser)帮忙整理成文。
Last updated on